Projects
This page documents my applied AI engineering and research projects, spanning LLM systems, retrieval-augmented generation, model compression, and production-grade ML pipelines.




Text-to-3D mesh generation using diffusion models
Tesseract v1 - Text-to-3D Mesh Generation System
Context & Motivation
I built Tesseract as my first flagship, end-to-end ML system to deliberately move beyond notebook-driven experiments and understand what separates production-grade AI systems from typical college-level projects..
Early-stage 3D asset creation is slow and labor-intensive, often forcing artists and developers to start from scratch before any meaningful iteration can begin. While text-to-3D diffusion models exist, most are released as fragile scripts or demos that are difficult to integrate into real workflows, lack reproducibility, and are not designed for deployment or scaling.
I wanted to explore how a research model could be wrapped into a reliable, scriptable, and scalable system, usable through real interfaces rather than isolated experiments.
Problem Statement
How can text-conditioned 3D mesh generation be exposed as a reliable, production-ready system suitable for batch workflows, service-based integration, and reproducible experimentation—rather than remaining a research demo or notebook artifact?
System Overview
Tesseract v1 is a modular, production-oriented ML pipeline that wraps a diffusion-based 3D generation model and exposes it through multiple interfaces:
- Stateless FastAPI service for supporting asynchronous, job-based mesh generation
- Custom CLI interface for local usage, batch generation and scripting
- Config-driven execution model (YAML-based) to enable reproducible runs and controlled experimentation
The system manages prompt ingestion, latent generation, mesh decoding, file export, and optional preview rendering in a unified pipeline. and is is intentionally designed to be stateless at the service layer, device-aware (GPU with CPU fallback), and structured in a way that is compatible with containerized deployment patterns.
Key Engineering Decisions
Rather than focusing on model novelty, I centered this project around system reliability, iteration ergonomics, and realistic integration constraints:
- Custom CLI with explicit flags for prompts, batching, output formats, and dry-runs, enabling reproducible experimentation outside notebooks
- Batch processing support to generate multiple samples per prompt, both to improve output selection and to stress-test the pipeline under heavier workloads
- Latent cache saving and resume support, allowing generation to continue from intermediate latent states instead of restarting full runs
- Asynchronous job handling to avoid blocking execution and support concurrent requests
- Modular system boundaries separating API, orchestration, decoding, rendering, and configuration layers
While initially attempting to extract only the minimal components required for text-to-3D generation, I found that Shape-E's research-oriented codebase was highly coupled, with core functionality spanning a large dependency graph. Rather than risk subtle breakage or silent correctness issues, I chose to vendor the full Shape-E project into the core, and build clean abstraction layers around it instead of aggressively pruning internals.
This decision favored correctness, stability, and debuggability over premature modularization.
Engineering & Stack
- Core: Python, PyTorch, Shape-E (text-conditioned diffusion)
- Interfaces: Custom CLI, FastAPI (REST)
- Execution: Async job orchestration, batch processing, latent caching
- Configuration: YAML-driven runtime configuration
- Observability: Structured logging across pipeline stages
- Deployment posture: Designed to be container-friendly and compatible with common Docker and Kubernetes deployment patterns
The focus was on keeping the system simple to reason about, easy to debug, and reproducible, rather than optimizing prematurely for scale.
Evaluation & Validation
Evaluation focused on system correctness and operational behavior, rather than benchmark scores:
- Qualitative inspection of generated meshes to assess usability as starting canvases
- Validation of batch execution under different memory and latency configurations
- Failure-mode testing around decoding, rendering, and partial pipeline crashes
- Verification that cached latents could reliably resume downstream stages
The emphasis was on ensuring the pipeline behaved predictably under iteration and failure, rather than optimizing for output aesthetics alone.
Limitations & Reflections
Several engineering choices emerged directly from repeated friction during development.
I introduced batch processing not only to increase the likelihood of obtaining useful outputs from stochastic diffusion, but also to intentionally stress-test the pipeline and observe how resource usage and failure modes surfaced under load.
Similarly, latent cache saving was added after encountering multiple cases where decoding or rendering failures—often due to small bugs or misconfigurations—forced the entire diffusion process to restart. Persisting intermediate latents significantly reduced wasted compute and made debugging faster and less frustrating.
Integrating a research codebase like Shape-E also highlighted the tradeoff between ideal modularity and practical correctness. This project reinforced that, in applied ML systems, stability and recoverability often matter more than architectural purity.
As my first flagship, end-to-end ML system, Tesseract helped solidify my understanding of what distinguishes robust engineering from experimental code: careful state management, clear boundaries, and designing for things to fail gracefully.
Status
Completed (v1) — a production-oriented architecture with clear scope for future improvements in model quality, evaluation rigor, and modular refinement.



July 2025
LLM-based user persona generation from Reddit activity
Reddit-Persona - LLM-based User Persona Generation
I built Reddit-Persona to explore how large language models can synthesize coherent behavioral personas from noisy, unstructured, real-world text data. This project originated as a pre-interview internship assignment, but I intentionally extended it beyond initial requirements to understand how LLMs behave when tasked with higher-level reasoning over fragmented user activity rather than direct question answering.
Context & Motivation
I was particularly interested in how design choices around chunking, context density, and output structure affect the quality and interpretability of persona-level outputs.
Problem Statement
How can we transform a Reddit user's scattered posts and comments—spanning multiple topics, tones, and timeframes—into a structured, interpretable persona, without overwhelming the model or losing important behavioral signals?
System Overview
Reddit-Persona is a modular pipeline that:
- Scrapes a user's public Reddit posts and comments using PRAW
- Cleans and filters the data to remove deleted or low-signal content
- Splits activity into topic-consistent text chunks (~2000 characters)
- Sends each chunk to a large language model for persona synthesis
- Produces multiple structured persona blocks, each grounded in a different slice of user behavior
The system supports both a CLI workflow for scripted runs and a Streamlit UI to make persona generation accessible to non-technical users.
Key Engineering Decisions
This project emphasized LLM interaction design and reasoning quality, rather than infrastructure scale:
- Chunk-based inference to preserve topical coherence and avoid diluting behavioral signals in long contexts
- Multiple persona generation (one per chunk) to capture micro-identities instead of forcing a single averaged profile
- Use of LLaMA-3.3-70B via Groq for persona synthesis, chosen for its strong instruction-following behavior and ability to produce structured, multi-facet analyses from unstructured text
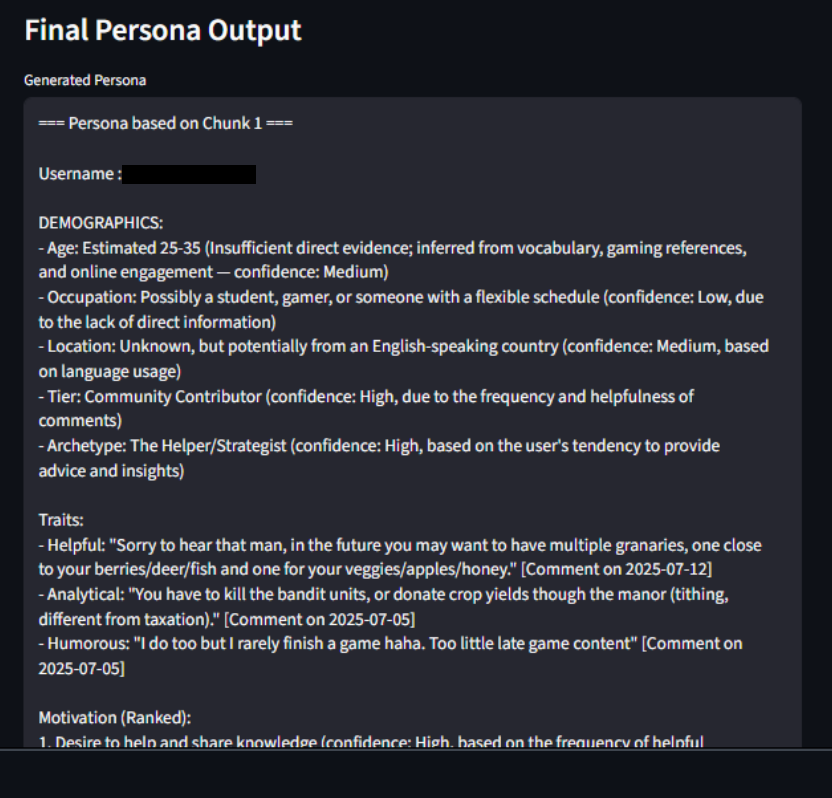
- Structured persona schema (traits, motivations, frustrations, goals, supporting quotes) to keep outputs interpretable and auditable
- Optional persona ranking logic to identify the most insight-rich persona block and explain why it was selected
- Streamlit UI integration, added beyond assignment requirements to study how such outputs are consumed in a visual, user-facing workflow
These decisions were driven by the goal of understanding how to reason with LLM outputs, not just generate text.
Model Choice Rationale
I chose LLaMA-3.3-70B for this task because persona synthesis requires semantic abstraction, consistency, and narrative grounding, rather than factual recall or short-form completion.
Compared to smaller models, LLaMA-70B demonstrated:
- Better stability across long, unstructured inputs
- More consistent persona traits across chunks
- Stronger adherence to structured output formats
Using Groq's inference API allowed fast, low-latency processing of multiple chunks per user, making iterative experimentation feasible without compromising output quality. This was particularly important given the chunk-based design of the system.
Engineering & Stack
- Language: Python
- Data access: PRAW (Reddit API Wrapper)
- LLM inference: Groq-hosted LLaMA-3.3-70B
- Interfaces: CLI (main.py) and Streamlit UI (app.py)
- Structure: Modular Python files for scraping, inference, formatting, and orchestration
- Environment management: Conda-based setup for dependency isolation
The project was intentionally kept simple from an infrastructure perspective to focus on reasoning quality, modularity, and clarity.
Evaluation & Validation
Evaluation was primarily qualitative and interpretive:
- Comparing persona blocks across chunks to assess behavioral consistency and diversity
- Verifying that extracted traits and motivations were grounded in explicit Reddit quotes
- Observing how chunk size and ordering affected persona richness and coherence
- Testing robustness against sparse activity, deleted content, and mixed-topic histories
The emphasis was on interpretability, traceability, and reasoning fidelity, rather than numerical benchmarks.
Limitations & Reflections
This project surfaced several important lessons.
Aggregating all user activity into a single prompt consistently degraded persona quality, reinforcing the importance of chunk-level reasoning. However, generating multiple personas introduced a new ambiguity: deciding which persona to trust. This motivated the addition of an experimental ranking step that re-evaluates persona blocks and selects the most insight-rich candidate, along with an explanation for the choice.
From an engineering standpoint, this was my first project where I became comfortable with clean Python project structuring, modular design, and environment isolation using Conda. While it does not yet include advanced logging or configuration separation, it laid the groundwork for how I structure larger systems today.
Finally, the project highlighted ethical and practical considerations around persona generation from real user data. For this reason, the system is not publicly hosted and requires users to supply their own API keys.
Status
Completed — a functional, reasoning-centric system that explores LLM-driven behavioral analysis and serves as an early foundation for more advanced applied and research-oriented work.



2025 - Present
Research-oriented LLM system for DevOps incident reasoning
MÍMIR - Research-Oriented LLM System
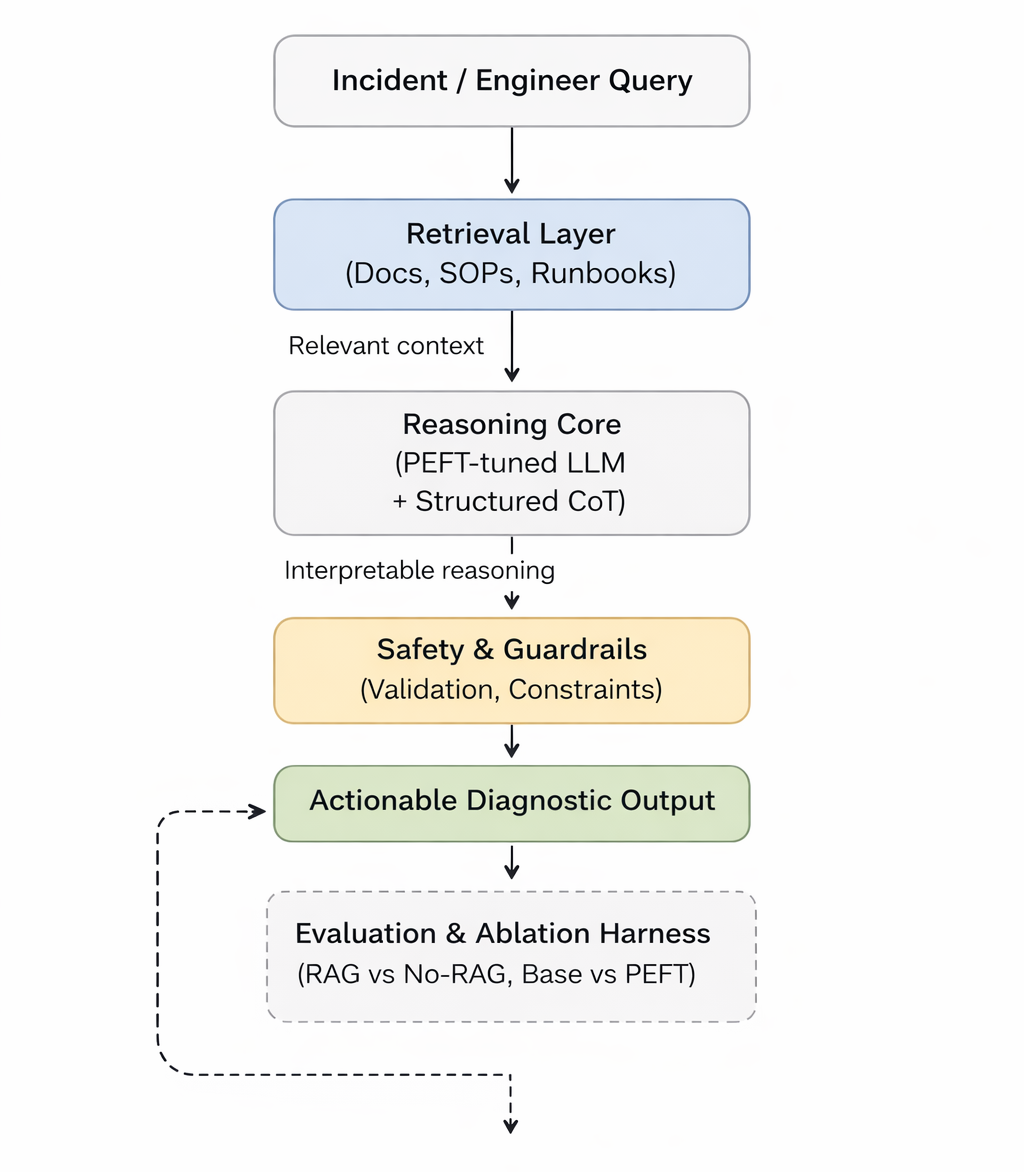
Designing a research-oriented LLM system to study retrieval-augmented reasoning and parameter-efficient adaptation under realistic system constraints. Emphasizes reproducible evaluation over application demos.
Key Features & Implementation:
- Retrieval-Augmented Reasoning: Advanced RAG implementation with multiple knowledge sources and fusion strategies.
- Parameter-Efficient Adaptation: LoRA and quantization techniques for resource-constrained deployment.
- System-Level Evaluation: Comprehensive metrics covering accuracy, latency, cost, and robustness.
- Reproducible Benchmarks: Standardized datasets and evaluation protocols for fair comparison.
- Production Constraints: Real-world considerations including memory limits, inference speed, and scalability.
Technical Stack:
RAG Systems, LoRA, Model Quantization, Evaluation Frameworks, System Optimization



Smart India Hackathon
Radar-vision research prototype for bird vs drone discrimination
SkySentinel-X — Micro-Doppler Target Classification (Research Prototype)
An exploratory radar–vision research system for bird vs drone discrimination using micro-Doppler signatures
Research Context & Motivation
SkySentinel-X is a research-oriented prototype built to investigate whether micro-Doppler signatures extracted from FMCW radar signals can be effectively transformed into a visual learning problem for modern deep learning models.
Low-altitude airspace monitoring systems frequently struggle to distinguish biological targets (birds) from small UAVs, leading to false alarms and unreliable threat assessment. Traditional radar pipelines rely on handcrafted features and heuristics, which often fail under real-world variability.
This project explores a different question: Can time–frequency representations of radar returns (STFT spectrograms) serve as a robust intermediate representation for CNN-based classification of aerial targets?
SkySentinel-X was developed as part of the Smart India Hackathon (SIH) problem statement on micro-Doppler–based target classification and successfully cleared the college-level selection round, validating its research direction and technical grounding.
Research Problem Statement
Objective: To experimentally evaluate whether deep convolutional models trained on STFT spectrograms can learn discriminative micro-Doppler patterns that separate birds from drone-like aerial objects.
Key research challenges addressed:
- High intra-class variability in drone rotor configurations
- Overlapping radar signatures between birds and UAVs
- Limited labeled radar datasets
- Class imbalance across target categories
- Translating radar signal processing outputs into ML-ready representations
System Overview (Research Pipeline)
SkySentinel-X implements a signal-processing → vision-learning pipeline, designed explicitly for experimentation and evaluation:
Radar Signal Processing
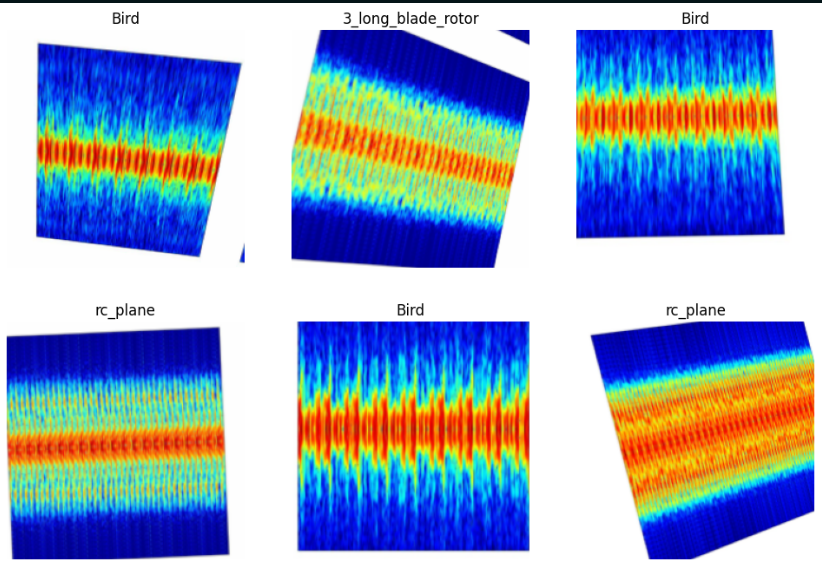
- FMCW radar returns processed using Short-Time Fourier Transform (STFT)
- Generation of micro-Doppler spectrograms capturing motion-induced frequency shifts
Representation Learning
- Spectrograms treated as image inputs
- Transfer learning using ResNet-50
- Fine-tuning restricted to later layers to adapt to radar-domain textures
Hierarchical Inference
- Multi-class predictions (rotor types, RC plane, bird)
- Aggregation into higher-level semantic groups: bird, drone
- Probability-weighted final decision with confidence estimation
This structure prioritizes interpretability and experimental control, not deployment.
Key Research & Engineering Decisions
Why STFT Spectrograms?
- Micro-Doppler effects manifest naturally in the time–frequency domain
- Spectrograms preserve: Rotor periodicity, Wing-flap harmonics, Motion-induced frequency spread
- Enables reuse of mature CNN architectures without handcrafted signal features
Why CNN Transfer Learning?
- Limited radar datasets make training from scratch impractical
- Pretrained CNNs provide strong low-level feature extractors
- Transfer learning allows rapid hypothesis testing under constrained data
Handling Dataset Bias
- Stratified splits to preserve class distribution
- Class-weighted loss to counter rotor-class dominance
- Augmentations designed to preserve spectrogram semantics
This project intentionally avoids over-engineering and instead focuses on clean experimental design.
Evaluation & Experimental Results
Dataset
- 813 labeled spectrogram samples
- Target categories: Bird, Drone, RC Plane, Long-blade rotor, Short-blade rotor
Results
- Overall accuracy: 94.71%
- Macro F1-score: 0.9479
Observations
- Near-perfect separation of biological vs mechanical targets
- Expected confusion between similar drone rotor configurations
- Strong generalization despite limited data volume
These results support the hypothesis that micro-Doppler spectrograms are a viable visual representation for aerial target classification.
Research Stack
Signal Processing
- FMCW radar data
- STFT-based time–frequency analysis
ML & Experimentation
- PyTorch + FastAI
- ResNet-50 (transfer learning)
- Class-weighted cross-entropy
- Early stopping and checkpointing
Analysis
- Confusion matrices
- Precision/recall/F1 analysis
- Training–validation loss tracking
Research Value & Applications
This project is positioned as a research probe, not a finished product.
Potential downstream relevance:
- Radar-based drone intrusion detection
- Bird–drone discrimination in aviation safety
- Defense and perimeter surveillance research
- Foundations for multimodal radar–vision systems
Its primary contribution is methodological: demonstrating a clean bridge between radar signal processing and deep visual learning.
Reflections & Learnings
SkySentinel-X represents an important shift in my work toward research-driven system design:
- Learned to reason across signal processing and ML abstraction layers
- Gained experience handling real-world class imbalance rigorously
- Developed intuition for radar-domain representations
- Practiced designing experiments that test hypotheses, not just models
While currently implemented as a notebook-based research prototype, the pipeline is intentionally structured to be refactored into modular training and inference systems in future iterations.
Project Status
Type: Research prototype
Stage: Experimental validation complete
Current form: Jupyter-based exploratory pipeline
Future work:
- Modularization into training/inference components
- Larger, more diverse radar datasets
- Real-time radar stream integration
- Extended aerial target taxonomy

College Research Project
Low-cost wearable computer vision glasses aid
ORCA v0 — Wearable Computer Vision Glasses Aid
Omni-Purpose Real-time Computer-vision Assistant (College Research Project)
Context & Motivation
Assistive smart glasses for visually impaired users exist, but they are typically proprietary, expensive (₹1–3 lakh / ~$1,200–$3,600), and tightly coupled to closed hardware and cloud-based inference.
ORCA v0 was built as a college research project to explore a fundamental question: Can modern open-source computer vision models be composed into a low-cost, real-time, wearable vision aid with meaningful assistive capabilities?
The project targeted a novel computer vision glasses concept, using commodity hardware and open-source models to prototype a system that could assist users with environmental awareness, navigation, and social interaction, while remaining affordable and privacy-preserving.
Problem Statement
How can we design a multi-purpose wearable computer vision system that:
- Operates in real time
- Supports multiple assistive use cases, not a single task
- Runs on low-cost hardware (₹800 ESP32-CAM ≈ $10)
- Avoids cloud dependency for privacy and latency
- Remains modular enough for experimentation and research
...rather than being a closed, single-purpose demo or a high-cost commercial device?
System Overview
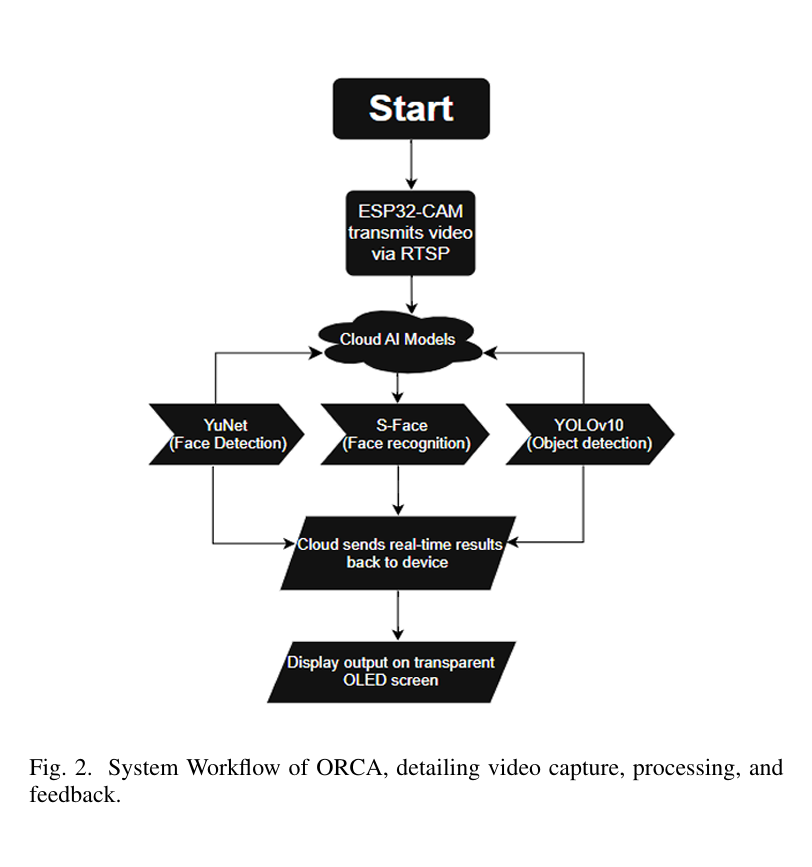
ORCA follows a hybrid edge-compute architecture designed for prototyping wearable vision systems:
- ESP32-CAM (~₹800 / ~$10) captures live video and streams frames wirelessly
- A local compute node (PC / edge system) performs all inference
- Multiple computer vision pipelines run in parallel
- Outputs are delivered via visual overlays and audio feedback
- Designed to integrate with a transparent OLED display for wearable glasses (prototype concept)
The system intentionally supports multiple use cases, not just one, making it closer to a general-purpose vision aid than a task-specific demo.
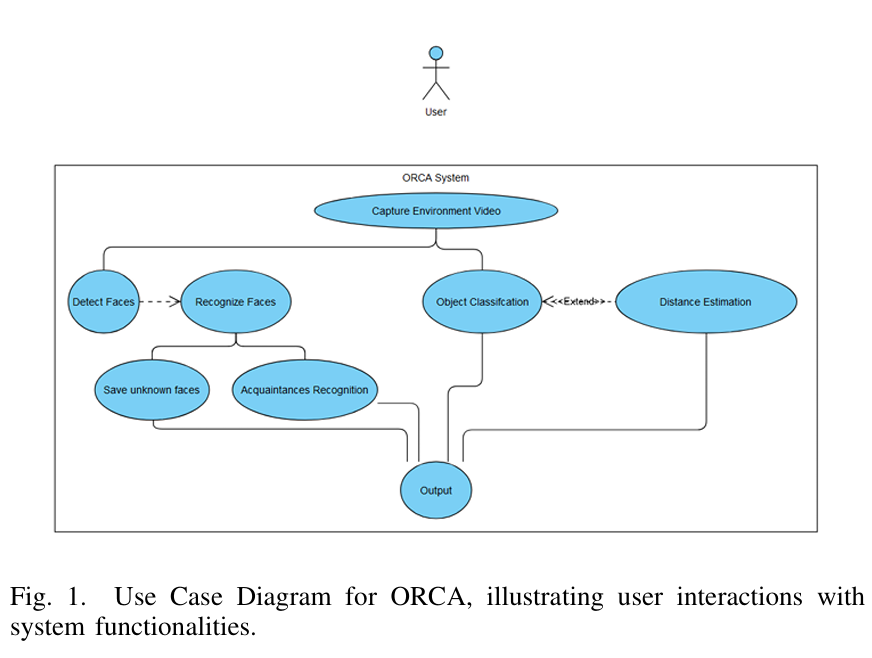
Core Use Cases Enabled
ORCA was designed to support and experiment with:
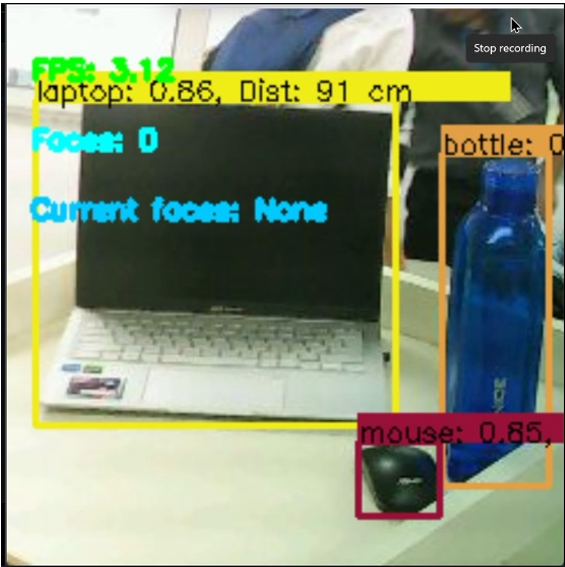
- Object Detection — Identifying common objects in the environment (80+ classes)
- Face Detection & Recognition — Identifying known vs unknown individuals with audio alerts
- Depth Estimation — Estimating relative distances for navigation and obstacle awareness
- Multi-Modal Assistance — Combining visual and audio cues to improve situational awareness
This multi-capability design was deliberate — most college projects focus on one vision task, whereas ORCA explored system-level integration across tasks.
Key Engineering Decisions
1. Multi-Model, Task-Specific Pipelines
Instead of forcing all tasks into a single model, ORCA uses specialized models per capability:
- YOLOv10 / NanoDet — real-time object detection
- YuNet + S-Face — face detection and recognition
- MiDaS / Depth Anything V2 — monocular depth estimation
This allowed independent benchmarking of accuracy vs latency, faster iteration and model swapping, and clear separation of concerns across pipelines.
2. Low-Cost Hardware Constraint
A strict constraint was using ESP32-CAM instead of high-end sensors or proprietary cameras. This forced realistic engineering trade-offs around frame resolution, network bandwidth, model size and inference speed, and end-to-end latency budgets. This constraint is what makes ORCA meaningful as a wearable assistive CV project, not just a desktop demo.
3. Privacy-Preserving, Local Inference
All inference runs locally: No cloud APIs for face recognition or object detection, no external transmission of sensitive visual data, suitable for assistive and accessibility-related contexts. This mirrors real-world constraints in assistive technology design.
4. Quantization for Real-Time Performance
Models were tested with INT8 quantization, reducing memory usage by ~40–50% while maintaining usable accuracy. This enabled ~8 FPS end-to-end processing, sub-second latency, and feasibility on consumer-grade hardware.
Engineering & Technology Stack
Languages & Frameworks: Python, OpenCV, PyTorch
Models: YOLOv10, NanoDet (object detection), YuNet, S-Face (face detection & recognition), MiDaS / Depth Anything V2 (depth estimation)
Hardware: ESP32-CAM (~₹800 / ~$10), Consumer PC / edge device
System Components: Wireless video streaming (HTTP), Parallel inference pipelines, Audio alert system, Visual debugging overlays
Evaluation & Validation
ORCA was tested across indoor and outdoor environments, focusing on practical usability rather than benchmark chasing.
Approximate observed performance:
- Object detection: ~93% mAP (COCO classes)
- Face detection: ~90% accuracy
- Face recognition: ~87% accuracy (local dataset)
- Depth estimation error: ±10 cm (0.5–3 m range)
- End-to-end throughput: ~8 FPS
These results validated the feasibility of a low-cost, multi-purpose wearable vision aid, though not production readiness.
Reflections & Learnings
This project marked an important transition from single-model demos to system-level computer vision engineering.
Key takeaways:
- Multi-model systems introduce orchestration and latency challenges not visible in notebooks
- Hardware constraints force better architectural decisions
- Real-time CV is about trade-offs, not just accuracy
- Assistive technology requires reliability and interpretability, not just performance
ORCA also revealed gaps — configuration management, logging, and abstraction — which directly informed the design of later projects like Tesseract and MÍMIR.
Limitations & Future Directions
Current limitations: Performance degrades in low-light conditions, Depth estimation adds significant latency, Configuration is partially hard-coded
Future improvements: Unified config and logging layers, Better low-light preprocessing, Spatial audio feedback, More capable edge hardware (Jetson / Raspberry Pi)
Status
Status: Completed (College Research Project)
Nature: Experimental research & prototyping
Outcome: Demonstrated feasibility of a low-cost, multi-purpose computer vision glasses aid




College Project & Hackathon
Edge-deployed contamination detection system
Vulkyrie v1 — Edge-Deployed Carcass Contamination Detection System
Low-cost, field-deployable computer vision and IIoT system for chemical contamination screening using color-based sensing and lightweight machine learning.
Context & Motivation
Monitoring chemical contamination in the field is often expensive, slow, and inaccessible, especially in rural or resource-constrained environments. In India alone, laboratory-grade chemical tests can cost ₹600–₹1200 ($7–$15) per sample, making large-scale or frequent monitoring impractical.
Vulkyrie was built as a low-cost, field-deployable computer vision and IIoT system to explore whether color-based sensing + lightweight machine learning can serve as an early-warning mechanism for chemical contamination.
This project specifically targeted Diclofenac contamination, a chemical linked to a catastrophic 99% collapse of India's vulture population, with severe downstream ecological and public-health consequences. The goal was not laboratory-grade accuracy, but rapid, accessible, and scalable screening.
Problem Statement
How can chemical contamination be detected cheaply, in real time, and in the field, using hardware that costs under ₹1000 ($12–$15), while still producing meaningful, interpretable outputs that can guide further investigation?
System Overview
Vulkyrie is an end-to-end research-to-prototype pipeline spanning:
- Data collection & chemical testing
- ML model training and analysis
- Edge deployment on ESP32 microcontrollers
- IIoT-style backend aggregation
- Geospatial visualization via a web dashboard
Rather than focusing purely on model accuracy, the system emphasizes deployment realism, hardware constraints, and operational usability.
Key Engineering Decisions
Random Forest Regression was chosen over deep models due to:
- Small, physically collected dataset
- Interpretability of decision paths
- Ease of pruning and simplification for microcontrollers
Edge-first design:
- Models were explicitly constrained to fit ESP32 memory and compute limits
Model-to-hardware translation:
- Full Random Forest logic was analyzed and reduced into threshold-based inference suitable for real-time execution
Data augmentation over brute-force modeling:
- Real chemical testing is costly and slow, so robustness was improved through controlled RGB noise injection
Centralized IIoT backend:
- Enables hotspot identification and geographic tracking of contamination events
Computer Vision & ML Pipeline
Input: RGB values from TCS3200 color sensor
Preprocessing:
- MinMax feature scaling
- Noise-based data augmentation (3× expansion)
Model:
- Pruned Random Forest Regressor (n_estimators=15, max_depth=5)
Outputs:
- Continuous contamination concentration
- Mapped to discrete risk levels: NEGATIVE, LOW, MODERATE, HIGH
Edge Deployment & Hardware
- Microcontroller: ESP32
- Sensor: TCS3200 color sensor
Inference:
- Simplified threshold logic derived from trained model
Interaction:
- Button-triggered sampling with reaction delay
- Serial output for debugging and logging
Cost:
- One-time hardware cost: ₹800–₹1000 ($10–$12)
- Per-test cost: ~₹100 (<$1)
This makes Vulkyrie orders of magnitude cheaper than conventional lab testing for preliminary screening.
Backend & Visualization
- REST API: Node.js + Express
- Database: PostgreSQL for structured storage
- Frontend: React + Leaflet
Interactive geographic contamination maps, centralized monitoring of distributed devices. Designed to simulate IIoT-style deployment, not just a standalone device.
Evaluation & Validation
Dataset:
- 24 physically collected chemical samples
- Augmented to 72 samples for robustness
Evaluation focused on:
- Consistency under lighting variation
- Stability of edge inference
- Qualitative agreement with known concentration levels
The system is explicitly positioned as early-warning & screening, not definitive diagnosis.
Reflections & Learnings
This project was intentionally ambitious for its scope and constraints. The most challenging aspects were:
- Real-world data collection involving chemical handling and concentration calibration
- Translating an ML model into resource-constrained embedded logic
- Understanding where engineering trade-offs matter more than raw model accuracy
- Designing systems that actually run outside notebooks
Vulkyrie was also one of the first projects where I deeply engaged with:
- Edge ML constraints
- Model simplification strategies
- Hardware–software co-design
- End-to-end system thinking beyond model training
Status
Stage: Experimental / Prototype
Context: College project & hackathon prototype
Readiness: Not production-grade, but technically validated
Positioning: Proof-of-concept for low-cost, AI-assisted contamination screening